21.6.2. The computing system¶
The distributed computing system¶
The large luminosity to be delivered by the Belle II experiment projects that we will handle tens of Peta bytes per year. To achieve the physics goals of the experiment, the data has to be reprocessed, distributed and analyzed. It is hard to expect that a single site provides the computing resources to manage such a large data set. Additionally, Belle II is a worldwide collaboration with more than 1000 scientists working in different regions of the planet. Therefore, it is natural to adopt a distributed computing architecture in order to access data and obtain physics results in a feasible time.
Key points
The main tasks of the computing system are:
Processing of raw data
Production of Monte Carlo samples.
Data preservation.
Skimming.
Analysis.
The Belle II distributed computing system (also known as the grid) is a form of computing where a “virtual super computer” is composed of many loosely networked computers. To the date, 60 computing sites and 35 storage elements contribute to the distributed computing resources, managed by central services hosted at KEK and BNL. This allow us to execute 20K jobs in a geographically distributed environment.
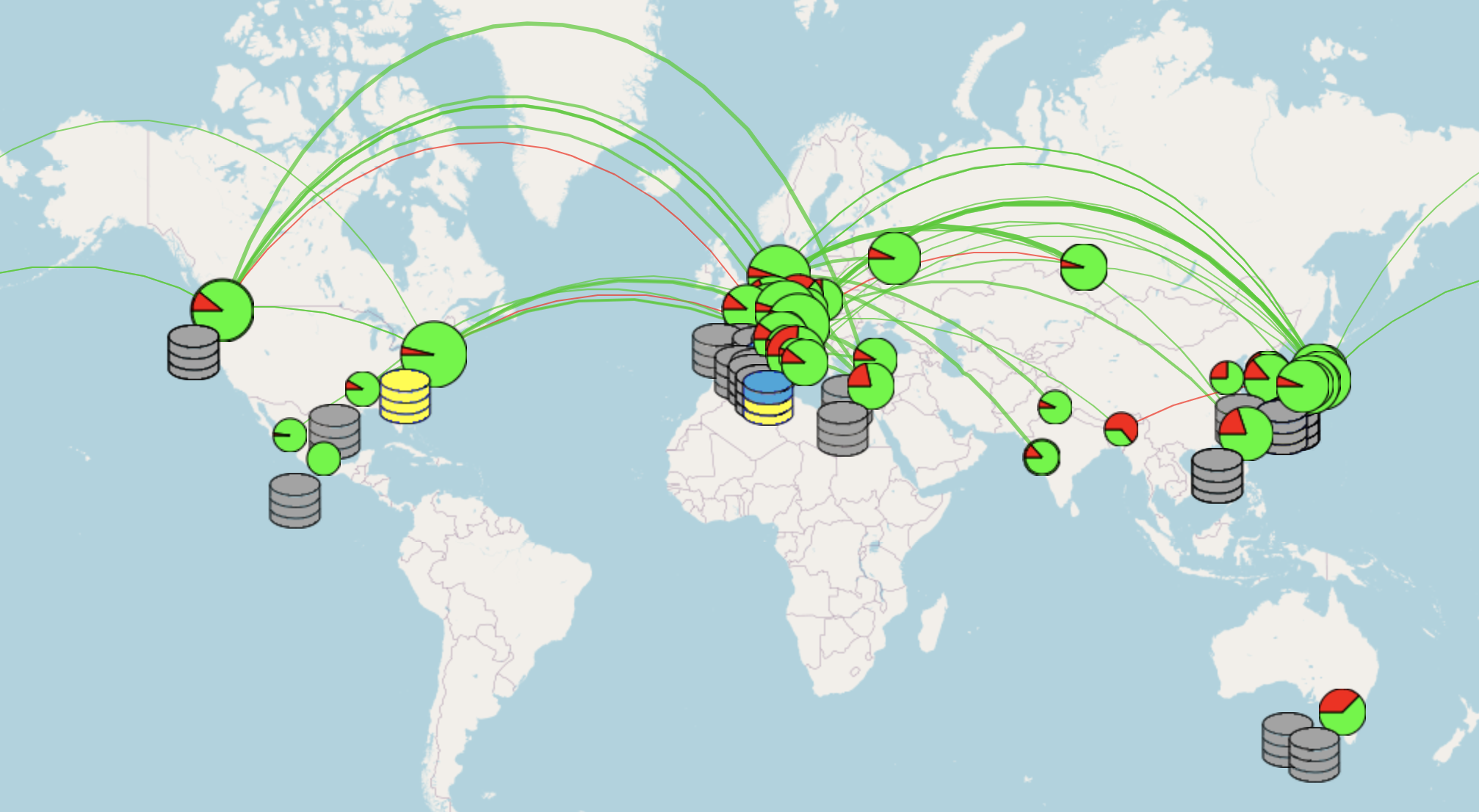
Fig. 21.33 Snapshot of the Belle II grid, composed by 60 computing sites around the world.¶
The Belle II grid uses the power of the DIRAC Distributed Computing Framework to control the jobs. An extension, BelleDIRAC, has been written for specific needs of the collaboration.
The client tools that communicate with DIRAC and BelleDIRAC have been organized in a set of tools named gbasf2. As an analyst, datasets are available for running analysis directly on the grid, download the output and perform the Offline analysis on local resources. One convenient feature of gbasf2 is it uses the same basf2 steering files used offline as input.
Key points
GBasf2 relies in the power of the DIRAC Distributed Computing Framework to control the jobs.
DIRAC uses X509 digital certificates to authenticate its users.
Therefore, you will need a certificate to submit jobs to the grid via gbasf2.
See also
“Computing at the Belle II experiment”, proceedings of the CHEP 2015 conference.
The details on how to run jobs and download the output are explained in the next chapter Gbasf2.
Data Processing Scheme¶
As mentioned before, on the grid the processing of the raw data is performed, as well as skimming and analysis and production of MC samples.
Raw data processing¶
In our computing model, all raw data produced by the experiment is uploaded and registered on the grid. After the calibration is performed, data is reprocessed in the raw data centers to produce MDST files.
Key points
All data is stored at KEK.
Dedicated data centers keep a second copy of the full raw data set.
Raw data is processed at the raw data centers to produce mDST files.
The mDST files are distributed over storage sites.
Analyzers access data sending jobs to the grid and downloading the output to local resources.
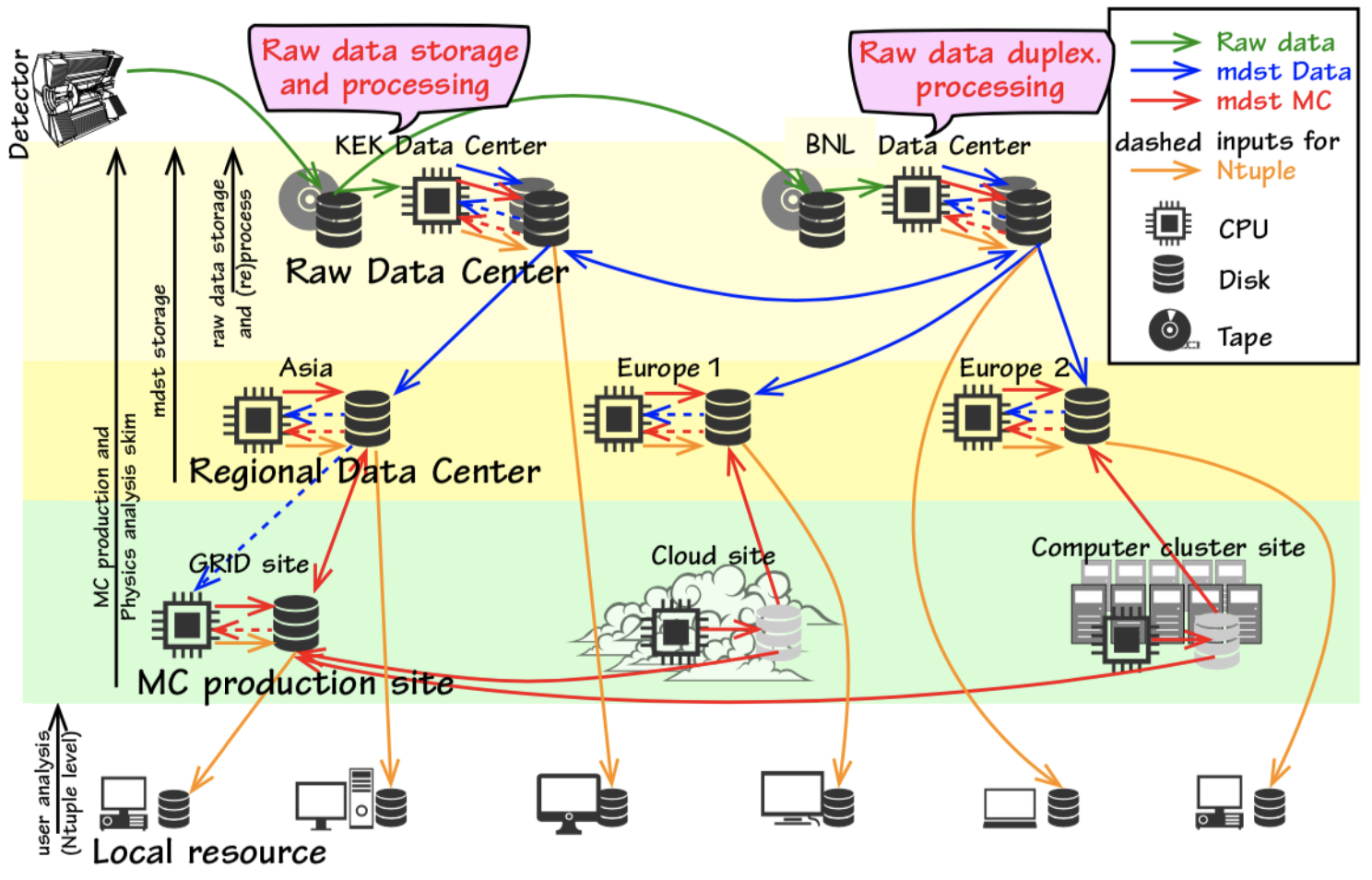
Fig. 21.34 The Belle II distributed computing model. Two copies of the raw data are stored and reprocessed at the raw data centers, in order to produce mdst files.¶
Monte Carlo samples¶
In parallel, Monte Carlo (MC) samples are centrally produced in campaigns labeled as MCXX, being ‘XX’ a sequential number (MC10, MC11, etc). Usually, every time a major basf2 release is available, a new campaign is launched. Details about the produced samples are usually available at the Data Production Confluence pages.
Note
While generic MC samples are produced every campaign, the data production liaisons of each working group are responsible for requesting the production of signal channels.
Tip
Look at the Data Production web home to know who is the DP liaison of your group. You will have to talk with him/her about your requirements every new campaign.
See also
“Belle II production system”, proceedings of the CHEP 2015 conference.
Skimming¶
Belle II is a multipurpose experiment. Each physics working group defines skims, which are also centrally managed and processed on the grid, producing uDST files. The purpose of skimming is producing data and MC files containing events who meet the criteria of each working group, reducing the size of the dataset to be analyzed and therefore the CPU time required to run the jobs over the samples.
The list of skims available can be found in the Skims documentation.
Note
It is strongly recommended that analysts use the skimmed uDST files rather than the original MDST files.
We need your help!¶
Computers are not so smart. Sometimes, they fail.
“Sometimes” x Huge Resources = “Often”
The computing system need 24 hour x 7 day care.
Please join us as a Data Production Shifter. You can book at shift.belle2.org (a very nice manual is already prepared).
If you have some experience as data production shifter, please become an expert shifter. The Expert Shifter training course is open.
You will learn a lot about the computing system, and it is a very important service to the collaboration.
Stuck? We can help!
If you get stuck or have any questions to the online book material, the #starterkit-workshop channel in our chat is full of nice people who will provide fast help.
Refer to Collaborative Tools. for other places to get help if you have specific or detailed questions about your own analysis.
Improving things!
If you know how to do it, we recommend you to report bugs and other requests
with JIRA. Make sure to use the
documentation-training component of the Belle II Software project.
If you just want to give very quick feedback, use the last box “Quick feedback”.
Please make sure to be as precise as possible to make it easier for us to fix things! So for example:
typos (where?)
missing bits of information (what?)
bugs (what did you do? what goes wrong?)
too hard exercises (which one?)
etc.
If you are familiar with git and want to create your first pull request for the software, take a look at How to contribute. We’d be happy to have you on the team!
Quick feedback!
Author of this lesson
Michel Villanueva