
Modules and Paths
Contents
5.1. Modules and Paths#
A typical data processing chain consists of a linear arrangement of smaller
processing blocks, called Modules. Their tasks vary
from simple ones like reading data from a file to complex tasks like the full
detector simulation or the tracking.
In basf2 all work is done in modules, which means that even the reading of data
from disk and writing it back is done in modules. They live in a
Path, which corresponds to a container where the
modules are arranged in a strict linear order. The specific selection and
arrangement of modules depend on the user’s current task. When processing data,
the framework executes the modules of a path, starting with the first one and
proceeding with the module next to it. The modules are executed one at a time,
exactly in the order in which they were placed into the path.
Modules can have conditions attached to them to steer the processing flow depending of the outcome of the calculation in each module.
The data, to be processed by the modules, is stored in a common storage, the DataStore. Each module has read and write access to the storage. In addition there’s also non-event data, the so called conditions, which will be loaded from a central conditions database and are available in the DBStore.
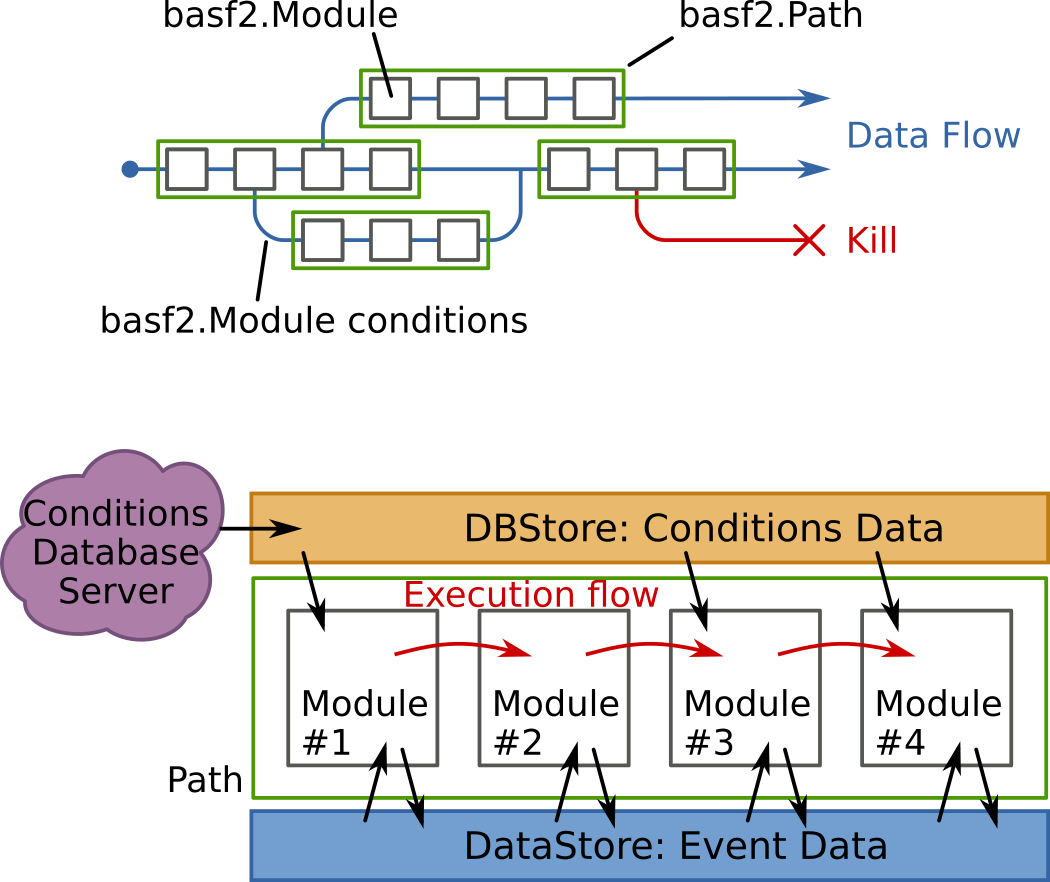
Fig. 5.1 Schematic view of the processing flow in the Belle II Software#
Usually each script needs to create a new path using Path(), add
all required modules in the correct order and finally call process on
the fully configured path.
Warning
Preparing a Path and adding Modules to it does not
execute anything, it only prepares the computation which is only done when
process is called.
The following functions are all related to the handling of modules and paths:
- basf2.create_path()[source]#
Creates a new path and returns it. You can also instantiate
basf2.Pathdirectly.
- basf2.register_module(name_or_module, shared_lib_path=None, logLevel=None, debugLevel=None, **kwargs)[source]#
Register the module ‘name’ and return it (e.g. for adding to a path). This function is intended to instantiate existing modules. To find out which modules exist you can run basf2 -m and to get details about the parameters for each module you can use basf2 -m {modulename}
Parameters can be passed directly to the module as keyword parameters or can be set later using
Module.param>>> module = basf2.register_module('EventInfoSetter', evtNumList=100, logLevel=LogLevel.ERROR) >>> module.param("evtNumList", 100)
- Parameters
name_or_module – The name of the module type, may also be an existing
Moduleinstance for which parameters should be setshared_lib_path (str) – An optional path to a shared library from which the module should be loaded
logLevel (LogLevel) – indicates the minimum severity of log messages to be shown from this module. See
Module.set_log_leveldebugLevel (int) – Number indicating the detail of debug messages, the default level is 100. See
Module.set_debug_levelkwargs – Additional parameters to be passed to the module.
Note
You can also use
Path.add_module()directly, which accepts the same name, logging and module parameter arguments. There is no need to register the module by hand if you will add it to the path in any case.
- basf2.set_module_parameters(path, name=None, type=None, recursive=False, **kwargs)[source]#
Set the given set of parameters for all
modulesin a path which have the givenname(seeModule.set_name)Usage is similar to
register_module()but this function will not create new modules but just adjust parameters for modules already in aPath>>> set_module_parameters(path, "Geometry", components=["PXD"], logLevel=LogLevel.WARNING)
- Parameters
path (basf2.Path) – The path to search for the modules
name (str) – Then name of the module to set parameters for
type (str) – The type of the module to set parameters for.
recursive (bool) – if True also look in paths connected by conditions or
Path.for_each()kwargs – Named parameters to be set for the module, see
register_module()
- basf2.print_params(module, print_values=True, shared_lib_path=None)[source]#
This function prints parameter information
- Parameters
module – Print the parameter information of this module
print_values – Set it to True to print the current values of the parameters
shared_lib_path – The path of the shared library from which the module was loaded
- basf2.print_path(path, defaults=False, description=False, indentation=0, title=True)[source]#
This function prints the modules in the given path and the module parameters. Parameters that are not set by the user are suppressed by default.
- Parameters
defaults – Set it to True to print also the parameters with default values
description – Set to True to print the descriptions of modules and parameters
indentation – an internal parameter to indent the whole output (needed for outputting sub-paths)
title – show the title string or not (defaults to True)
- basf2.process(path, max_event=0)[source]#
Start processing events using the modules in the given
basf2.Pathobject.Can be called multiple times in one steering file (some restrictions apply: modules need to perform proper cleanup & reinitialisation, if Geometry is involved this might be difficult to achieve.)
When used in a Jupyter notebook this function will automatically print a nice progress bar and display the log messages in an advanced way once the processing is complete.
Note
This also means that in a Jupyter Notebook, modifications to class members or global variables will not be visible after processing is complete as the processing is performed in a subprocess.
To restore the old behavior you can use
basf2.core.process()which will behave exactly identical in Jupyter notebooks as it does in normal python scriptsfrom basf2 import core core.process(path)
- Parameters
path – The path with which the processing starts
max_event – The maximal number of events which will be processed, 0 for no limit
Changed in version release-03-00-00: automatic Jupyter integration
5.1.1. The Module Object#
Unless you develop your own module in Python you should always instantiate new
modules by calling register_module or Path.add_module.
- class basf2.Module#
Base class for Modules.
A module is the smallest building block of the framework. A typical event processing chain consists of a Path containing modules. By inheriting from this base class, various types of modules can be created. To use a module, please refer to
Path.add_module(). A list of modules is available by runningbasf2 -morbasf2 -m package, detailed information on parameters is given by e.g.basf2 -m RootInput.The ‘Module Development’ section in the manual provides detailed information on how to create modules, setting parameters, or using return values/conditions: https://confluence.desy.de/display/BI/Software+Basf2manual#Module_Development
- available_params() list :#
Return list of all module parameters as
ModuleParamInfoinstances
- beginRun() None :#
This function is called by the processing just before a new run of data is processed. Modules can override this method to perform actions which are run dependent
- description() str :#
Returns the description of this module.
- endRun() None :#
This function is called by the processing just after a new run of data is processed. Modules can override this method to perform actions which are run dependent
- event() None :#
This function is called by the processing once for each event.Modules should override this method to perform actions during event processing
- get_all_condition_paths() list :#
Return a list of all conditional paths set for this module using
if_value,if_trueorif_false
- get_all_conditions() list :#
Return a list of all conditional path expressions set for this module using
if_value,if_trueorif_false
- has_condition() bool :#
Return true if a conditional path has been set for this module using
if_value,if_trueorif_false
- has_properties((int)properties) bool :#
Allows to check if the module has the given properties out of
ModulePropFlagsset.>>> if module.has_properties(ModulePropFlags.PARALLELPROCESSINGCERTIFIED): >>> ...
- Parameters
properties (int) – bitmask of
ModulePropFlagsto check for.
- if_false(condition_path, after_condition_path=AfterConditionPath.END)#
Sets a conditional sub path which will be executed after this module if the return value of the module evaluates to False. This is equivalent to calling
if_valuewithexpression=\"<1\"
- if_true(condition_path, after_condition_path=AfterConditionPath.END)#
Sets a conditional sub path which will be executed after this module if the return value of the module evaluates to True. It is equivalent to calling
if_valuewithexpression=\">=1\"
- if_value(expression, condition_path, after_condition_path=AfterConditionPath.END)#
Sets a conditional sub path which will be executed after this module if the return value set in the module passes the given
expression.Modules can define a return value (int or bool) using
setReturnValue(), which can be used in the steering file to split the Path based on this value, for example>>> module_with_condition.if_value("<1", another_path)
In case the return value of the
module_with_conditionfor a given event is less than 1, the execution will be diverted intoanother_pathfor this event.You could for example set a special return value if an error occurs, and divert the execution into a path containing
RootOutputif it is found; saving only the data producing/produced by the error.After a conditional path has executed, basf2 will by default stop processing the path for this event. This behaviour can be changed by setting the
after_condition_pathargument.- Parameters
expression (str) – Expression to determine if the conditional path should be executed. This should be one of the comparison operators
<,>,<=,>=,==, or!=followed by a numerical value for the return valuecondition_path (Path) – path to execute in case the expression is fulfilled
after_condition_path (AfterConditionPath) – What to do once the
condition_pathhas been executed.
- initialize() None :#
This function is called by the processing just once before processing any data is processed. Modules can override this method to perform some actions at startup once all parameters are set
- name() str :#
Returns the name of the module. Can be changed via
set_name(), usetype()for identifying a particular module class.
- package() str :#
Returns the package this module belongs to.
- param(key, value=None)#
This method can be used to set module parameters. There are two ways of calling this function:
With two arguments where the first is the name of the parameter and the second is the value.
>>> module.param("parameterName", "parameterValue")
Or with just one parameter which is a dictionary mapping multiple parameter names to their values
>>> module.param({"parameter1": "value1", "parameter2": True})
- return_value((int)value) None :#
Set a return value. Can be used by custom modules to set the return value used to determine if conditional paths are executed
- set_abort_level((int)abort_level) None :#
Set the log level which will cause processing to be aborted. Usually processing is only aborted for
FATALmessages but with this function it’s possible to set this to a lower value- Parameters
abort_level (LogLevel) – log level which will cause processing to be aborted.
- set_debug_level((int)debug_level) None :#
Set the debug level for this module. Debug messages with a higher level will be suppressed. This function has no visible effect if the log level is not set to
DEBUG- Parameters
debug_level (int) – Maximum debug level for messages to be displayed.
- set_log_info((int)arg2, (int)log_info) None :#
Set a
LogInfoconfiguration object for this module to determine how log messages should be formatted
- set_log_level((int)log_level) None :#
Set the log level for this module. Messages below that level will be suppressed
- Parameters
log_level (LogLevel) – Minimum level for messages to be displayed
- set_name((str)name) None :#
Set custom name, e.g. to distinguish multiple modules of the same type.
>>> path.add_module('EventInfoSetter') >>> ro = path.add_module('RootOutput', branchNames=['EventMetaData']) >>> ro.set_name('RootOutput_metadata_only') >>> print(path) [EventInfoSetter -> RootOutput_metadata_only]
- set_property_flags((int)property_mask) None :#
Set module properties in the form of an OR combination of
ModulePropFlags.
- terminate() None :#
This function is called by the processing once after all data is processed. Modules can override this method to perform some cleanup at shutdown. The terminate functions of all modules are called in reverse order of the
initializecalls.
- type() str :#
Returns the type of the module (i.e. class name minus ‘Module’)
5.1.2. The Path Object#
- class basf2.Path#
Implements a path consisting of Module and/or Path objects (arranged in a linear order).
See also
- __contains__()#
Does this Path contain a module of the given type?
>>> path = basf2.Path() >>> 'RootInput' in path False >>> path.add_module('RootInput') >>> 'RootInput' in path True
- __reduce__()#
Helper for pickle.
- add_independent_merge_path(skim_path, ds_ID='', merge_back_event=None, consistency_check=None, event_mixing=False, merge_same_file=False)#
Merge specified content of DataStore of independent path into DataStore of main path on a per event level (add tracks/cluster from both events,…).
- Parameters
skim_path – independent path to be merged
ds_ID – can be specified to give a defined ID to the temporary DataStore, otherwise, a random name will be generated (option for developers).
merge_back_event – is a list of object/array names (of event durability) that will be merged back into the main path.
consistency_check – perform additional consistency checks on the objects from two paths. If they are not satisfied, the skim_path proceeds to the next event on the path. Currently supported value is “charge” that uses EventExtraInfo “charge” of the two paths, that must be specified by the user, ensuring correct configuration of the combined event. See CheckMergingConsistencyModule for more details.
event_mixing – apply event mixing (merge each event from first path with each event of second path)
merge_same_file – merge events from single file (useful for mixing)
- add_independent_path(skim_path, ds_ID='', merge_back_event=None)#
Add given path at the end of this path and ensure all modules there do not influence the main DataStore. You can thus use modules in skim_path to clean up e.g. the list of particles, save a skimmed uDST file, and continue working with the unmodified DataStore contents outside of skim_path.
- Parameters
ds_ID – can be specified to give a defined ID to the temporary DataStore, otherwise, a random name will be generated.
merge_back_event – is a list of object/array names (of event durability) that will be merged back into the main path.
- add_module(module, logLevel=None, debugLevel=None, **kwargs)#
Add given module (either object or name) at the end of this path. All unknown arguments are passed as module parameters.
>>> path = create_path() >>> path.add_module('EventInfoSetter', evtNumList=100, logLevel=LogLevel.ERROR) <pybasf2.Module at 0x1e356e0>
>>> path = create_path() >>> eventinfosetter = register_module('EventInfoSetter') >>> path.add_module(eventinfosetter) <pybasf2.Module at 0x2289de8>
- add_path(path)#
Insert another path at the end of this one. For example,
>>> path.add_module('A') >>> path.add_path(otherPath) >>> path.add_module('B')
would create a path [ A -> [ contents of otherPath ] -> B ].)
- Parameters
path (Path) – path to add to this path
- do_while(path, condition='<1', max_iterations=10000)#
Similar to
add_path()this will execute a path at the current position but it will repeat execution of this path as long as the return value of the last module in the path fulfills the givencondition.This is useful for event generation with special cuts like inclusive particle generation.
See also
Module.if_valuefor an explanation of the condition expression.- Parameters
path (basf2.Path) – sub path to execute repeatedly
condition (str) – condition on the return value of the last module in
path. The execution will be repeated as long as this condition is fulfilled.max_iterations (int) – Maximum number of iterations per event. If this number is exceeded the execution is aborted.
- for_each(loop_object_name, array_name, path)#
Similar to
add_path(), this will execute the givenpathat the current position, but in each event it will execute it once for each object in the given StoreArrayarrayName. It will create a StoreObject namedloop_object_nameof same type as array which will point to each element in turn for each execution.This has the effect of calling the
event()methods of modules inpathfor each entry inarrayName.The main use case is to use it after using the
RestOfEventBuilderon aParticeList, where you can use this feature to perform actions on only a part of the event for a given list of candidates:>>> path.for_each('RestOfEvent', 'RestOfEvents', roe_path)
You can read this as
“for each
RestOfEventin the array of “RestOfEvents”, executeroe_path”For example, if ‘RestOfEvents’ contains two elements then
roe_pathwill be executed twice and during the execution a StoreObjectPtr ‘RestOfEvent’ will be available, which will point to the first element in the first execution, and the second element in the second execution.See also
A working example of this
for_eachRestOfEvent is to build a veto against photons from \(\pi^0\to\gamma\gamma\). It is described in How to Veto.Note
This feature is used by both the Flavor Tagger and Full event interpretation algorithms.
Changes to existing arrays / objects will be available to all modules after the
for_each(), including those made to the loop object itself (it will simply modify the i’th item in the array looped over.)StoreArrays / StoreObjects (of event durability) created inside the loop will be removed at the end of each iteration. So if you create a new particle list inside a
for_each()path execution the particle list will not exist for the next iteration or after thefor_each()is complete.- Parameters
loop_object_name (str) – The name of the object in the datastore during each execution
array_name (str) – The name of the StoreArray to loop over where the i-th element will be available as
loop_object_nameduring the i-th execution ofpathpath (basf2.Path) – The path to execute for each element in
array_name
- modules()#
Returns an ordered list of all modules in this path.