25.4.1. The basics.¶
The Belle II software is called basf2. It is an abbreviation for “Belle II Analysis Software Framework”. You may see also “BASF2” or “Basf2” in some outdated documentation, but the official way for writing it is basf2, using only lower case letters. You might wonder why we didn’t choose “b2asf”, and when you get a bit further you will probably wonder why it has “analysis” in the name (it does much more than analysis)? Well historic reasons: Belle had BASF, we have basf2.
basf2 is used in all aspects of the data-processing chain at Belle II:
generating simulated data,
unpacking of real raw data,
reconstruction (tracking, clustering, …),
and high-level “analysis” reconstruction (such as applying cuts, vertex-fitting, …).
basf2 is not normally used for the final analysis steps (histogramming, fitting 1D distributions, …). These final steps are usually called the “offline” analysis and will be covered in later lessons Offline analysis.
There is a citable reference for basf2:
Kuhr, T. et al. Comput Softw Big Sci 3, 1 (2019) https://doi.org/10.1007/s41781-018-0017-9
… and a logo.

Fig. 25.18 The basf2 logo.¶
Pragmatically, you will encounter two separate objects named basf2.
It is both a command-line executable which you can invoke, and a python
module from which you import functions.
You will soon be running commands that look like:
basf2 myScript -i myInputFile.root
… and inside the scripts you might see code like:
from basf2 import Path
mypath = Path()
Core concepts¶
There are some concepts we use in basf2, which you will definitely need to understand. These are:
basf2 module,
path,
package,
steering script / steering file.
Most of the other jargon terms we use are generic software development terms (so you can search the internet). A good place to look for Belle II-specific jargon is the Belle II Glossary.
Exercise
Find the Belle II Glossary (again).
Hint
You might need to revisit the tutorial pages about Collaborative Tools..
Solution
basf2 modules¶
A basf2 module is a piece of (usually) C++ code that does a specific “unit” of data processing. The full documentation can be found here in this website under the section Modules and Paths.
Warning
It is an unfortunate clash of naming that python uses the word “module” for a separate concept. In these tutorials we will always specify python module (and basf2 module) if there is ambiguity.
Path¶
A basf2 path is an ordered list of modules that will be used to process the
data.
You can think of building a path by adding modules in a chain.
It is a python object: basf2.Path.
Warning
A common misconception is that adding modules to a path is processing data. This is not true, you will prepare your path for data-processing by adding modules. The event-loop starts when you process your path.
Exercise
Find a diagram of a path with modules in this documentation.
Hint
I have already given you a link to the relevant page.
Solution
Take a look at the Modules and Paths page. The diagram is here.
Package¶
A package is a logical collection of code in basf2. A typical package has several modules and some python scripts which configure paths to do common things.
You will encounter some basf2 packages in these lessons. We try to give them meaningful names (tracking, reconstruction, …) or name the package after the subdetector that they are related to (ecl, klm, cdc, top, …).
During these lessons, you will mostly interact with the analysis package. You will meet this at the end of this lesson.
Exercise
Find the source code and find a list of all packages.
Hint
You might need to revisit the tutorial pages about Collaborative Tools..
Solution
The source code is online here. The list of packages is simply the list of directories in the software directory.
Steering¶
A steering file or a steering script is some python code that sets up some
analysis or data-processing task.
A typical steering file will declare a basf2.Path, configure basf2 modules,
and then add them to the path.
Then it will call basf2.process and maybe print some information.
We use the word “steering” since no real data processing is done in python.

Fig. 25.19 The C++ and python logos.¶
Question
Why do we use both C++ and python?
Solution
Generally speaking, the heavy data processing tasks are done in C++. This is because of the performance. Python is used as a user-friendly and readable language for configuration.
Note
There are some exceptions, some modules are written in python for instance, but they are not very common.
Databases¶
There are a couple more concepts that you might come across:
the conditions database
and the run database.
For these lessons and exercises you should not need to know too much but it’s good to be aware of the jargon.
See also
See also
See also
“rundb” in the glossary (no link this time, you should have it bookmarked!)
Key points
basf2 is the name of the Belle II software.
You work in basf2 by adding modules to a path.
Most basf2 modules are written in C++.
Data-processing happens when you process the path.
You do all of this configuration of the path, etc in python in a steering file.
You can navigate this online documentation.
Tip
After you’ve progressed a bit more through these lessons, you should revisit the Modules and Paths documentation page and reread the opening paragraphs.
By that stage everything should be clear.
Getting started, and getting help interactively¶
Now let’s setup the environment, actually execute basf2, and navigate the
command line help.
Please ssh onto your favourite site.
If you do not have a preference, you should connect to login.cc.kek.jp.
Before we start though…
You shouldn’t need to install anything¶
A common misconception by newcomers (and even by senior people in the collaboration), is that you need to “install” basf2 or “install a release”.
It is possible to install from scratch, but you almost certainly do not want or need to do this. If you are working at KEK (for certain) and at many many other sites, basf2 is available preinstalled. It is distributed by something called /cvmfs.
b2setup¶
To set up your environment to work with basf2 you first have to source the
setup script…
source /cvmfs/belle.cern.ch/tools/b2setup
Some people like to put an alias to the setup script in their .profile (or
.bashrc, .zshrc, …) file.
You are welcome to do this if you like.
So now you have a Belle II environment.
You might have noticed that you still don’t have the basf2 executable:
$ source /cvmfs/belle.cern.ch/tools/b2setup
Belle II software tools set up at: /cvmfs/belle.cern.ch/tools
$ basf2
command not found: basf2
Note: we only used the $ character to distinguish the commands from the
expected output, it should not be typed.
In order to get the basf2 executable you need to choose a release
(a specific version of the software).
If you don’t know what release you want, you should take the latest stable
full release or the latest light release (see below).
There is a command-line tool to help with this. Try:
b2help-releases --help
To setup the release of your choice simply call b2setup again with the
name of your release.
Since you’ve already set up the environment, the b2setup executable itself
is already in your PATH (that means we don’t need the full path /cvmfs/.../b2setup anymore):
b2setup <your choice of release>
See also
If you already know what release you want, you can do the first and second step in one go:
source /cvmfs/belle.cern.ch/tools/b2setup <your choice of release>
Note that if you setup an unsupported, old, or strange release you should see a warning:
$ b2setup release-01-02-09
Environment setup for release: release-01-02-09
Central release directory : /cvmfs/belle.cern.ch/el7/releases/release-01-02-09
Warning: The release release-01-02-09 is not supported any more. Please update to ...
Sometimes people have good reason to use old releases but you should know that you will get limited help and support if you are using a very old version.
And you expose yourself to strange bugs that will not be fixed in your version (because they are fixed in some later release).
It is also true that using the latest supported release makes you cool.
Exercise
There is a detailed page in this documentation describing the differences between a full release and a light release and also a Belle II question.
Hint
There is no hint. You’ve got this.
Solution
It is described in the section Choosing a release.
Question
What is semantic versioning?
Hint
This is jargon but it is not specific to Belle II.
Solution
A rule for version numbers. See the summary at https://semver.org
Question
If you have code that worked in release-AA-00-00 will it work in
release-AA-01-00 ?
Solution
Yes. There should not be anything that breaks backward compatibility between minor versions.
Question
If you have code that worked in release-AA-00-00 will it work in
release-BB-00-00 ?
Solution
No, it is not guaranteed. Unfortunately there is no guarantee of backward compatibility between major versions. And for good reason: sometimes things need to be changed to introduce new features.
Question
If you have code that worked in light-5501-future will it work in
light-5602-reallyfarfuture ?
Solution
No, it is not guaranteed. Unfortunately there is no guarantee of backward compatibility between light releases. And for good reason: sometimes things need to be changed to introduce new features. For more information: Do light releases break backward compatibility?.
Exercise
Typically there are two supported full releases. What are they?
Hint
b2help-releases # no arguments
Solution
It will be the current recommended full release and the one previous. So execute:
b2help-releases
And then subtract one from the major version number.
Exercise
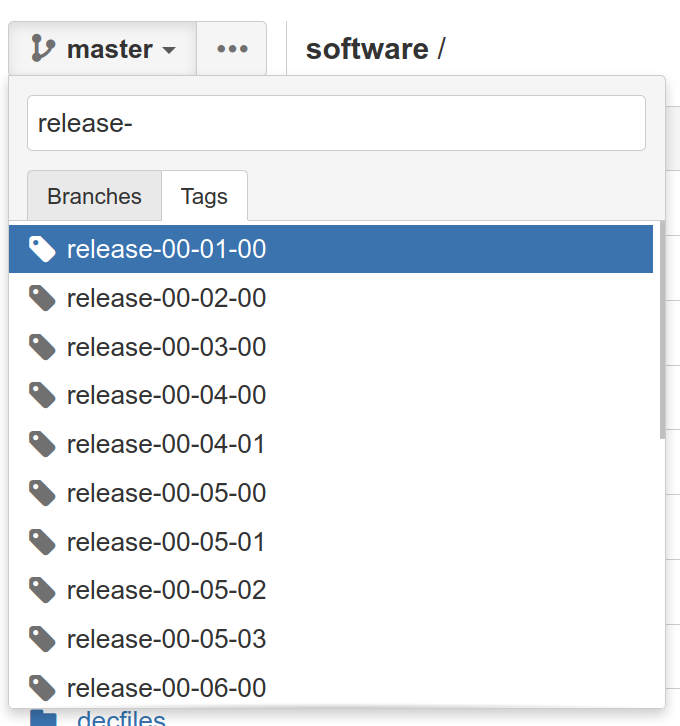
Find the source code for the recommended full release.
Hint
We use git to tag releases. You might need to revisit the lesson on collaborative tools.
Solution
Click on “source”.
At the top it probably says “master”. Choose the drop-down menu.
Click on “tags” and search for the release tag.
A useful command¶
If you’re ever stuck and you are writing a post on questions.belle2.org or an email to an expert they will always want to know what version you are using.
Try
basf2 --info
to check everything was set up correctly. If that worked, then paste the information at the bottom (after the ascii art) into any correspondence with experts.
Help at the command line¶
There are quite a lot of standard python tools/ways to get you help at the command line or in an interactive environment. The Belle II environment supports pydoc3.
Try:
pydoc3 basf2.Path
You should notice that this is the same documentation that you will find by
clicking on: basf2.Path here in this online documentation.
In addition, there are some basf2-specific commands.
Listing the basf2 modules¶
To find information about a basf2 module, try:
b2help-modules # this lists all of them
b2help-modules | grep "Particle"
b2help-modules ParticleCombiner
Listing the basf2 variables¶
In the next lessons, you will need to refer to physics quantities in plain text format. basf2 defines many variables for you. These variables are collected in something called the VariableManager.
To check the list of basf2 variables known to the VariableManager, run
b2help-variables
b2help-variables | grep "invariant"
There is a Variables section in this documentation which you might find more helpful than the big dump.
See also
Listing the modular analysis convenience functions¶
We have a python module full of useful shorthand functions which configure
basf2 modules in the recommended way.
It is called modularAnalysis.
More on this later.
For now, you can list them all with:
basf2 modularAnalysis.py
basf2 particles¶
Sometimes you will need to write particles’ names in plain text format. basf2 adopts the convention used by ROOT, the PDG, EvtGen, …
To show information about all the particles and properties known to basf2,
there is a tool b2help-particles.
b2help-particles --pdg 313 # how should I write the K*(892)?
b2help-particles B_s # what was the pdg cod of the B-sub-s meson again?
b2help-particles Sigma_b- # I've forgotten the mass of the Sigma_b- !
b2help-particles Upsi # partial names are accepted
#b2help-particles # lists them all (this is a lot of output)
Note
In the next lesson you will need to use these names.
Question
What was the luminosity collected in experiment 8?
Hint
There is a command line tool for that.
Try tabcompletion b2<tab>.
Another hint
$ b2info-<tab>
Are you sure you really need another hint?
$ b2info-luminosity --help
Solution
$ b2info-luminosity --exp 8 --what offline
Read 697 runs for experiment 8
TOTAL offline : L = 5464553.60 /nb = 5464.55 /pb = 5.465 /fb = 0.0055 /ab
So the answer is \(\sim 5.5\textrm{ fb}^{-1}\).
It didn’t work
Did you get an error like this?
[INFO] ===Error Summary================================================================
[FATAL] DB /group/belle2/dataprod/Luminosity/OffLineLuminosity.db not found. The live luminosity is only available on KEKCC (sorry)
[INFO] ================================================================================
Sorry about that. Can you try this command at KEK ? This should be fixed properly soon.
Other useful features¶
If you just execute basf2 without any arguments, you will start an IPython session with many basf2 functions imported. Try just:
basf2
In your IPython session, you can try the basf2 python interface to the PDG database:
In [1]: import pdg
In [2]: whatisthis = pdg.get(11)
In [3]: print(whatisthis.GetName(), whatisthis.Mass())
You should also make use of IPython’s built-in documentation features.
In [4]: import modularAnalysis
In [5]: modularAnalysis.reconstructDecay?
In [6]: # the question mark brings up the function documentation in IPython
In [7]: print(dir(modularAnalysis)) # the python dir() function will also show you all functions' names
You can remind yourself of the documentation for a basf2.Path in yet another way:
In [8]: import basf2
In [9]: basf2.Path?
In [10]: # the question mark brings up the function documentation in IPython
In [11]: # this is equivalent to...
In [12]: print(help(basf2.Path))
To leave interactive basf2 / IPython, simply:
In [13]: # exit()
In [14]: # ... or just
In [15]: exit
Other useful things in your environment¶
You might notice that setting up the basf2 environment means that you also have tools like ROOT, and (an up-to-date version of) git.
These come via the Belle II externals. We call software “external” if is not specific to Belle II but used by basf2.
See also
If you are interested, you can browse the list of everything included in the externals in this README file.
Some python packages that are useful for final offline analysis are also included in the externals for your convenience. These are tools such as numpy and pandas. You will meet them in the Offline analysis lessons.
Key points
b2setupsets up the environment.You need to setup a specific release and you should try and keep up-to-date.
b2help-releasesb2setup <choose a release>b2help-particlesbasf2 has a python interface. You can use python tools to find help.
basf2without any tools gets you into a basf2-flavoured IPython shell.
The basf2 analysis package¶
The analysis package of basf2 contains python functions and C++ basf2 modules to help you perform your specific analysis on reconstructed dataobjects. It will probably become your favourite package.
The collection of “reconstructed dataobjects” is actually a well-defined list. You will hear people call these “mdst dataobjects”. The “mdst” is both a file-format and another basf2 package containing the post-reconstruction dataobjects.
Exercise
Find the documentation for the analysis package and read the first two sections.
Hint
There is no hint. You’ve got this.
Solution
Exercise
Find a list of mdst dataobjects.
Solution
There are (at least) two ways to do this.
You can look at the function source code for
mdst.add_mdst_output.You can browse the mdst/dataobjects directory in the basf2 source code: https://stash.desy.de/projects/B2/repos/basf2/browse/mdst/dataobjects/include
The important mdst dataobjects are:
Track (and TrackFitResult)
ECLCluster
KLMCluster
PIDLikelihood
MCParticle
See also
“mdst” in the glossary
Earlier we asked some questions about code backward-compatibility. We can now take a brief diversion into the second kind of backward-compatibility that is guaranteed in the software.
Mdst backward-compatibility is guaranteed for the last two major releases.
See also
The confluence page Software Backward Compatibility
Question
If you have an mdst file that was created in release-AA-00-00
will you be able to open it with release-BB-00-00?
Solution
Yes. If BB is AA+1 (i.e. the next major release). You should be able to open the old file, and your analysis code should work.
Question
If you have an mdst file that is from the latest MC campaign. Will you be able to open it with the latest light release?
Solution
Yes. New light releases will always be able to open files from the current, and last supported full release. An MC campaign is always based on a full release.
You will use mdst data files in the next lesson.
Let’s get back to thinking about the reconstructed dataobjects. An important point to understand is that the analysis package interprets collections of these dataobjects as particle candidates.
In brief:
A track (with or without a cluster and with or without PID information) is interpreted as a charged particle (\(e^\pm\), \(\mu^\pm\), \(\pi^\pm\), \(K^\pm\), or \(p^\pm\)).
A cluster with no track in close vicinity is interpreted as a photon or a \(K_L^0\).
Two or more of the above particles can be combined to make composite particle candidates. For example:
Two photons can be combined to create \(\pi^0\to\gamma\gamma\) candidates.
Two tracks can be combined to create \(K_S^0\to\pi^+\pi^-\) candidates.
… And so on.
In fact, the analysis package mostly operates on ParticleList s. A ParticleList is just the list of all such particle candidates in each event. In the next lesson you will make your own particle lists and use analysis package tools to manipulate them.
Making your life easier¶
Suggested configuration of the analysis package basf2 modules is usually done for you in so-called “convenience functions”. Certainly all the modules needed for these lessons.
The python module containing these functions is called modularAnalysis.
You have already met the modularAnalysis convenience functions
earlier in this lesson: Listing the modular analysis convenience functions.
You are encouraged to look at the source code for the modularAnalysis
convenience functions that you find yourself using often.
In pseudo-python you will see they are very often of the form:
1import basf2
2
3def doAnAnalysisTask(<arguments>, path):
4 """
5 A meaningful and clear docstring. Sometimes quite long-winded.
6 Occasionally longer than the active code in the function.
7
8 Details all of the function inputs...
9
10 Parameters:
11 foo (bar): some input argument
12 path (basf2.Path): modules are added to this path
13 """
14 # register a module...
15 this_module = basf2.register_module("AnalysisTaskModule")
16 # configure the parameters...
17 this_module.param('someModuleParamter', someValue)
18 # add it to the path...
19 path.add_module(this_module)
Question
What is the ParticleCombiner module? What does it do?
Hint
You can use either
basf2 -m ParticleCombiner
or browse this online documentation.
Solution
The ParticleCombiner takes one or more ParticleList s
and combines Particle s from the inputs to create composite particle
candidates.
See also
Exercise
Find the modularAnalysis convenience function that wraps the
ParticleCombiner module?
Read the function.
Solution
You want the modularAnalysis.reconstructDecay function.
You could either read the source code for that on stash,
or find it here in this documentation and click “[source]”.
Congratulations! You are now ready to write your first steering file. Good luck.
See also
While the next sections will help you to understand the basics of steering files step by step, there are also some comple examples for steering files in the main software repository. You might want to take a look there after the starterkit.
Stuck? We can help!
If you get stuck or have any questions to the online book material, the #starterkit-workshop channel in our chat is full of nice people who will provide fast help.
Refer to Collaborative Tools. for other places to get help if you have specific or detailed questions about your own analysis.
Improving things!
If you know how to do it, we recommend you to report bugs and other requests
with JIRA. Make sure to use the
documentation-training component of the Belle II Software project.
If you just want to give very quick feedback, use the last box “Quick feedback”.
Please make sure to be as precise as possible to make it easier for us to fix things! So for example:
typos (where?)
missing bits of information (what?)
bugs (what did you do? what goes wrong?)
too hard exercises (which one?)
etc.
If you are familiar with git and want to create your first pull request for the software, take a look at How to contribute. We’d be happy to have you on the team!
Quick feedback!
Author of this lesson
Sam Cunliffe