
23.2.1. SVD Track Finding#
The VXDTF2 is the standalone pattern recognition algorithm for both of the silicon detectors. It is capable of doing full 6 layer tracking (SVD+PXD). Though in the current tracking chain PXD hits are treated separately thus the VXDTF2 is used for SVD track finding only. In this page there is a brief description of the logic behind this pattern recognition algorithm.
Reduction of the combinatorial burden with the SectorMaps#
The goal is to extract track patterns from a huge number of possible combinations of space points (3D hits) in the 4 SVD layers. The logic behind the reduction of the number of combinations is the following: divide the sensors into sectors (NxM). Only combine SpacePoints belonging to friend-sectors, where two sectors are defined as friend if they are directly connected by a track. Background SpacePoints are rejected using dedicated filters which use simple geometric relations between sectors and hit time information.
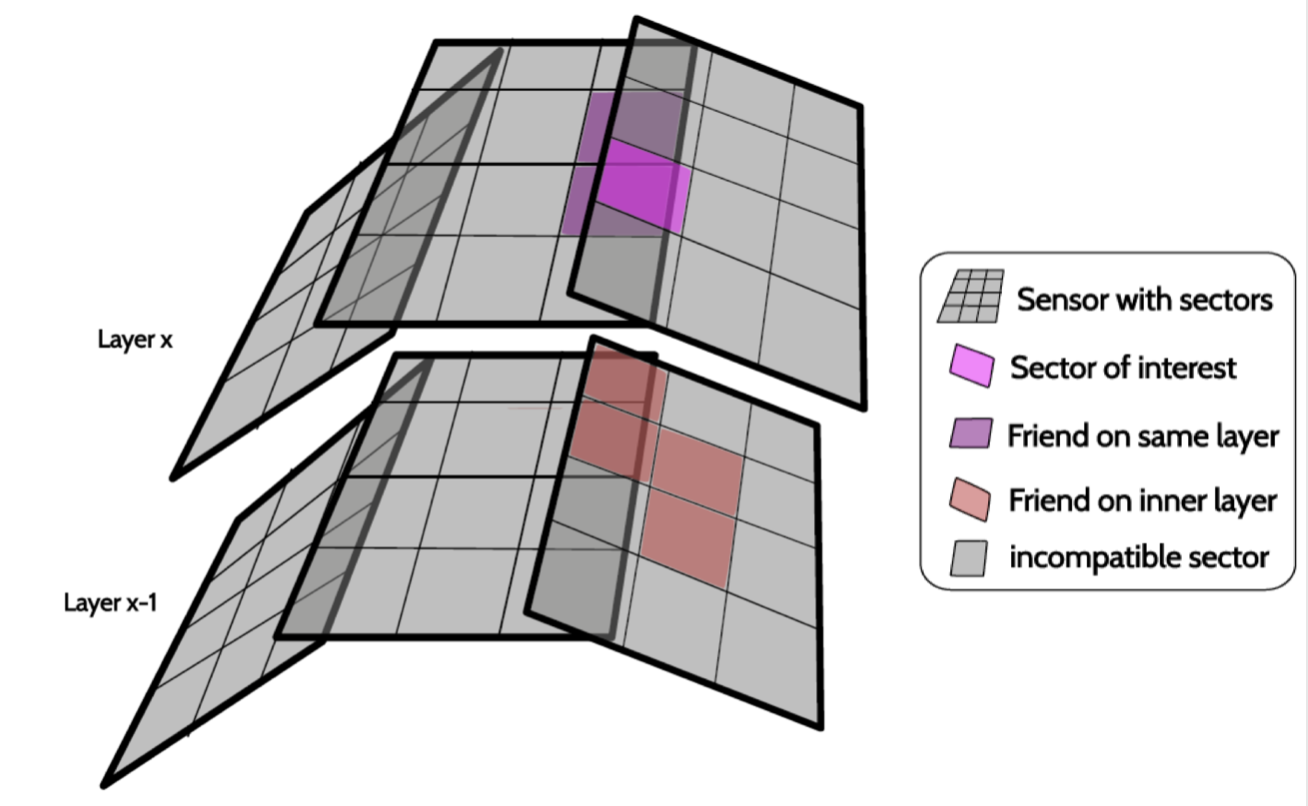
The connections defining friend sectors are learned from simulation. In order to avoid attaching background hits to patterns, filters based on 2- or 3-hit combinations are also learned from simulation. The SectorMap stores the information about the friendship relations between sectors and a set of selection requirements (filters = {variable, range}) used to reject background hits. The filters are defined (and stored in the SectorMap) individually for each occurring combination of friend sector relations, meaning that different combination of friend sectors usually have different ranges for the filters defined.
Simplified view of the friendship relations
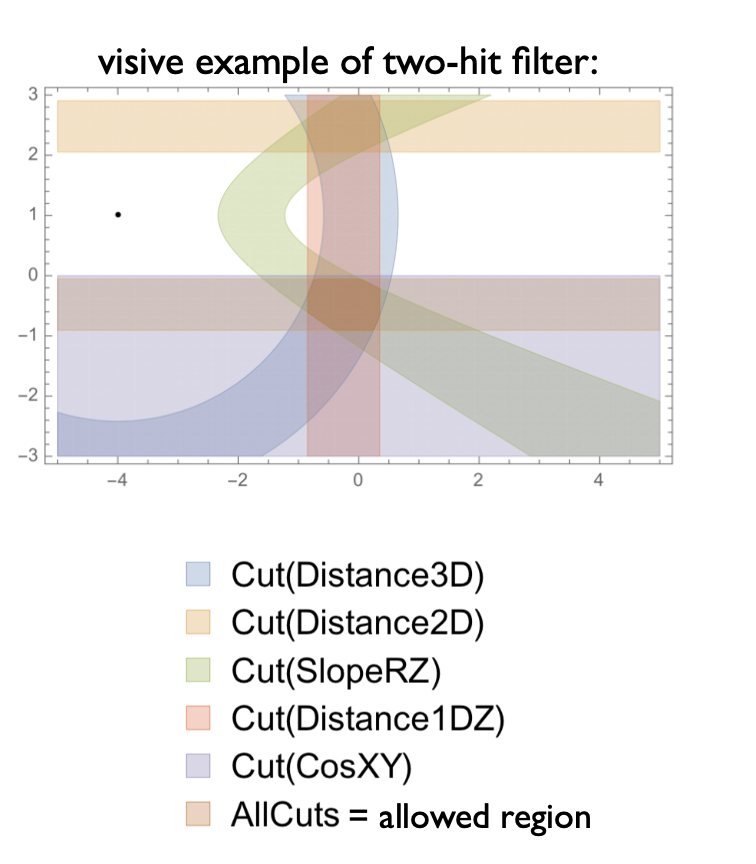
Two-hit filter example
Variables used in the filters are geometric (distances, slopes) or properties of the SVD clusters, like the cluster time. There are two types of filters defined within the framework. There are 2-hit filters, for the selection of 2-hit combination, and 3-hit filters, for the selection of 3-hit combinations, defined. Variables used in the current implementation of filters are listed in the following tables. For 2-hit filters are following variables used:
variables for 2-hit filter |
description |
|---|---|
Distance3DSquared |
squared distance of the two SpacePoints |
Distance3DNormed |
squared distance in the x-y plane divided by the 3D distance sqared of the two SpacePoints |
Distance2DXYSquared |
xy squared distance of the two SpacePoints in the x-y plane |
Distance1DZ |
distance of the two SpacePoints in the z direction |
SlopeRZ |
angle between the z direction and the direction defined by the two Space Points |
DistanceInTimeUside |
time difference of the two u-side clusters of the SpacePoints |
DistanceInTimeVside |
time difference of the two v-side clusters of the SpacePoints |
For 3-hit filters a larger variety and more complex quanities can be calculated due to the information the third hit is adding. The 3-hit filters currently used in the SectorMap are the following:
variables for 3-hit filters |
description |
|---|---|
DistanceInTime |
time difference between u- and v- cluster of the center hit (of the 3-hit combination) |
Angle3DSimple |
cosine of the 3D angle between inner-center and center-outer arms of the 3-hit combination |
CosAngleXY |
cosine of the 2D angle in the x-y-plane between inner-center and center-outer arms of the 3-hit combination |
AngleRZSimple |
cosine of the angle between inner-center and center-outer arms in the r-z-plane |
CircleDist2IP |
calculates the distance of the point of closest approach of the circle to the IP |
DeltaSlopeRZ |
calculates deviations in the slope of the inner segment and the outer segment |
DeltaSlopeZoverS |
compares the “slopes” of z over arc length |
DeltaSoverZ |
calculates the helixparameter describing the deviation in arc length per unit in z |
HelixParameterFit |
calculates the helixparameter describing the deviation in z per unit angle |
Pt |
calculates the estimate of the transverse momentum of the 3-hit-tracklet |
CircleRadius |
calculates the estimate of the circle radius of the 3-hit-tracklet |
Note the names for the variables in the tables are the same as the class names used in the implementation.
The allowed range for each filter is learned from simulation, filling the distribution of the variable during the training and defining thresholds for min and max at the 0.1% and 99.9% quantiles, respectively. Using the friendship relations and the filters, segments connecting two, three or four SpacePoints are built. At this stage a single SpacePoint can be shared by more than one segment and we are ready to build track candidates that are identified and collected by a Cellular Automaton.
SectorMap Training#
The training of the SectorMap is a critical step for the performance of the pattern recognition. Important aspects of the training are:
division of the sensor in sectors: we use a 4x4 division
sample used for the training (size, types of simulated events): we use \(10\times10^6\ B\bar{B}\) + \(2\times 10^6\) Bhabha events, both samples have additional muon tracks mixed in using the
ParticleGunpruning: removal of friendship relations that are less used: the threshold is set at 70%
difference in misalignment between simulation and real detector: we train on perfectly aligned MC, for data we now use a geometry using alignment data.
Further details on the SectorMap training and a detailed description of steps to be taken to train a SectorMap can be found under:
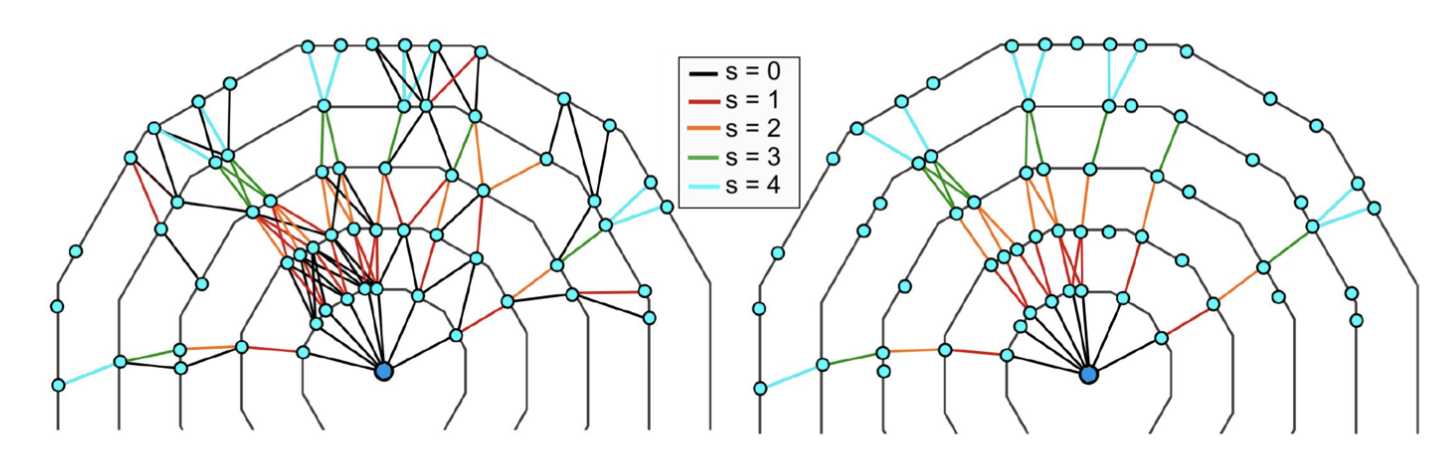
Track Candidates identified by the Cellular Automaton#
The SectorMaps is used to produce the Segment Network, a set of segments (a pair of SpacePoints) that satisfy the friendship relations and the filters. A Cellular Automaton which uses segments as cells is run to gather the longest paths.
Best Candidate Selection#
We do not allow that track candidates found by the VXDTF2 share common hits. To achieve that a best candidate selection is performed. At the moment two algorithms are implemented to perform the best candidate selection which can be chosen by a Module parameter.
One is the so called Hopfield which builds a Hopfield network out of all track candidates and performs an optimization on that network. The resulting set of output track candidates do not share any hits among each other.
The second algorithm is a so called greedy algorithm. It selects from the initial set of track candidates the one with the highest quality based on the output of a quality estimator. This track candidate is removed from the initial set of track candidates and put into the final set of track candidates. In addition all track candidates which share at least one hit with this track candidate are removed from the initial set of track candidates. This procedure is repeated until the initial set of track candidates is empty. The output is the final set of track candidates. Currently a simple Triplet fit is used as quality estimator:
a Triplet Fit is applied to each path and sub paths obtained by excluding one or more space points
for each track candidate the sum of the chi2 of each triplet is computed
the p-value of each track candidate is used to select the track candidates competing for one or more space points
During operation it was observed that the Hopfield algorithm is significantly slower compared to the greedy algorithm. For that reason the greedy algorithm is applied which is much faster than the Hopfield while shows similar performance in terms of efficiency and fake rate.